

/insights report
I asked Claude Code to run a usage report on my Claude Code sessions from the last two weeks. Around 200 sessions, 235 hours, across game dev, mobile apps, multi-agent tooling, and infrastructure. I'm publishing the redacted version because it's a useful snapshot of how one person is actually working with AI coding agents in 2026, and because if you sell dev tools, your buyer might look more like this than you think.
Three things worth flagging before you read it:
The "developer" in this report barely writes code by hand. I work top-down. PRDs get decomposed into dependency-linked issues, multi-persona reviews happen before implementation, then agent swarms ship the work. Claude Code is less pair programmer, more fleet commander. Your next wave of adopters is evaluating your tool through an agent, not by reading your quickstart.
Most of my friction is in the orchestration layer, not the code. Race conditions between parallel agents claiming the same ticket. Output token limits cutting off mid-batch. OAuth expiring inside Docker containers. These are the real problems once you scale one human to many agents.
What I'm building on the back of this:
A self-coordinating agent dispatch system with atomic ticket claims and auto-rebase
An end-to-end PRD-to-shipped-feature pipeline triggered by a single command
Test-harness-driven loops where agents iterate against real app states until a spec passes
If you run an API or SDK company and this pattern of work is showing up in your own usage data, that's the shift I help companies navigate. Reach out at philjohnstonii.com if you want to compare notes.
The full report is below.
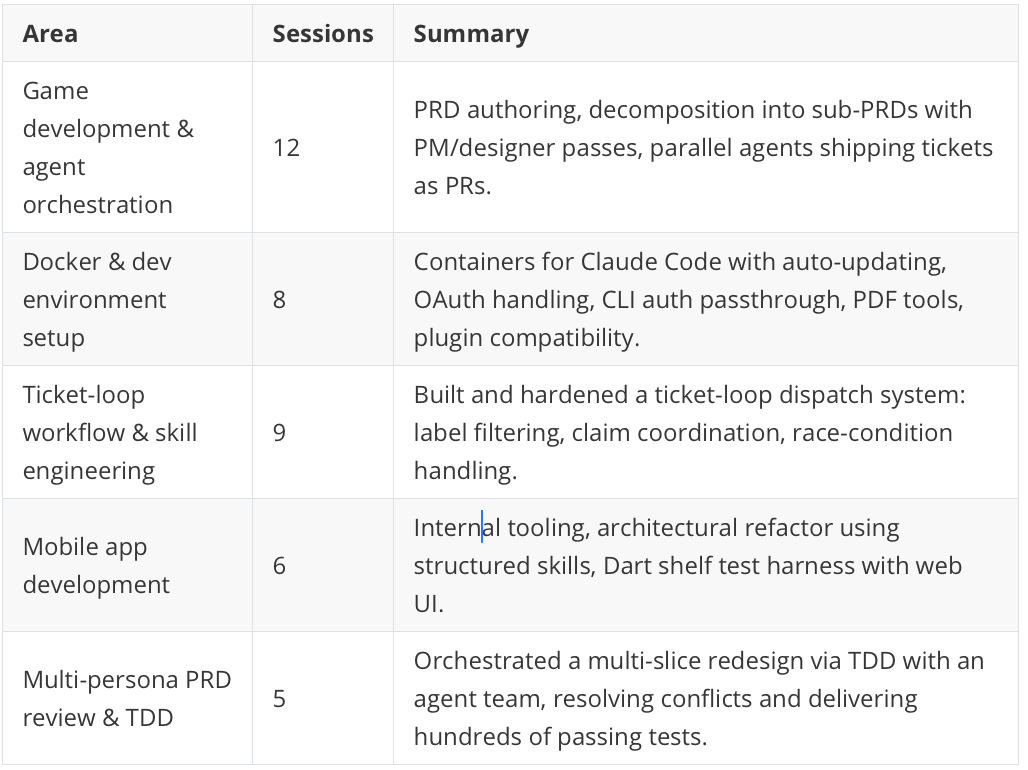
Session summary: ~200 sessions over ~2 weeks, ~235 hours of work across a mix of game development, mobile app work, multi-agent dispatch tooling, and infrastructure.
At a Glance
What's working: I operate top-down and spec-first. PRDs get decomposed into dependency-linked sub-issues, multi-persona reviews happen before code, and then agent swarms ship the work. Examples: a game project decomposed from a large PRD into enriched sub-issues and shipped via parallel agents, and a mobile app feature rollout delivered via TDD with hundreds of passing tests.
What's hindering: On Claude's side, multi-agent dispatch has race conditions (duplicate claims, merge conflicts, stale labels), and output-token limits silently truncate responses mid-batch. On my side, Docker and auth friction blocks work before it starts (OAuth expirations, missing container tools, CLI auth passthrough), and long batch jobs aren't checkpointed, so hitting a usage window mid-run wastes real progress.
Quick wins: Hooks to enforce a pre-claim verification step on ticket-loop workflows (atomic label claim + already-done check) so duplicate-claim rates drop without babysitting. Lean into headless mode for batch enrichment passes: invoke Claude per-item from a shell loop so each issue is its own checkpointed unit rather than one giant session.
Ambitious workflows: As models get stronger, the orchestration layer becomes the leverage point. Chain PRD decomposition → multi-persona review → ticket-loop → test-harness verification into one command. Invest now in making harness profiles and assertions machine-readable so agents can close the loop themselves.
Project Areas
Interaction Style
I operate at a high level of orchestration. Claude Code is less like a pair programmer and more like a fleet commander. Sessions are dominated by multi-agent dispatch workflows: ticket-loop prompts, parallel agents, concurrent PR shipping. I think in terms of skills, workflows, and reusable infrastructure. When I play Snake, I don't just want to win, I want a reusable script and agent guide afterward.
I tend toward detailed upfront specs followed by long autonomous runs. I let Claude work extensively (sessions frequently hit usage window limits mid-batch), and I'm comfortable with brainstorm → spec → plan → implement pipelines. But I'm not passive. I interrupt decisively when Claude drifts off-course. When Claude pushed clarifying questions instead of acting, I redirected. The friction pattern shows "wrong approach" as my top friction: I course-correct based on approach mismatches, not bugs.
I'm remarkably tolerant of infrastructure friction and treat it as part of the work. A large chunk of sessions are meta-work: making the harness work, making plugins work in Docker, making CLIs authenticate inside containers. Satisfaction stays high even when sessions get cut short, suggesting I view these as expected costs of running at scale rather than failures.
Key pattern: A systems orchestrator who specs thoroughly, dispatches autonomous agent fleets, and intervenes surgically only when the approach drifts. Claude Code is infrastructure to be tuned, not a tool to be driven.
What's Working
Parallel agent ticket dispatch. Built and iteratively hardened a system for dispatching concurrent agents to ship tickets autonomously. When race conditions caused duplicate claims, I didn't abandon the approach: I added claim detection, label-based coordination, and case-insensitive filtering to harden the skill.
Spec-driven PRD decomposition. Work top-down from PRDs to structured execution: large PRD → dependency-linked sub-PRDs → enriched with PM and designer passes. The discipline of separating design, planning, and execution phases is why multi-agent workflows actually land.
Test harness and QA tooling. Rather than debugging reactively, I invested in building a Dart shelf-based test harness with profiles, shortcuts, screenshot paste, and guided walkthroughs to validate app states.
Friction Analysis
Multi-agent coordination race conditions
When parallel agents ship tickets, they step on each other because claim detection is weak. Stronger locking (atomic label claims, check-before-work guards) upfront would prevent wasted cycles.
Session and output limits interrupting long workflows
Repeatedly hit usage windows and output-token caps mid-task on batch operations that can't easily resume. Breaking work into smaller checkpointed chunks or front-loading critical output would reduce lost progress.
Environment and authentication blockers
Docker-heavy setup combined with OAuth token expiration repeatedly blocks work before it starts. Pre-flight auth checks and building missing tools into the container image would eliminate recurring dead-ends.
Suggestions
CLAUDE.md additions
Ticket-loop workflow
Always check for existing claim comments and already-shipped status before starting work
Use case-insensitive label filters in jq queries
Never force-remove worktrees without checking for active agent sessions
After shipping a PR, verify labels applied and check for merge conflicts with siblings
Docker environment constraints
Document missing tools (pbcopy, poppler-utils, etc.) so Claude handles them proactively
Use stable ports for services exposed from the container
Host paths from plugins may need compatibility symlinks
Response length
Keep individual responses concise; output token limits cause API errors mid-task
For large batch work, break into smaller commits or checkpoint progress so a truncated response doesn't lose work
Features to try
FeatureWhy it fitsCustom skillsAlready used heavily. Add a /ship-pr skill bundling ship-branch logic with label/claim/merge-conflict checks.HooksA PostToolUse hook running a formatter on edited files prevents whitespace friction. PreToolUse could block worktree force-removal when an agent lock exists.Headless modeConcurrent ticket-dispatch is exactly what this is built for. Replacing CLI-in-Docker auth complexity with claude -p could eliminate 401 errors and simplify the pipeline.
Usage patterns
Checkpoint long batch work. Write a progress file after each item so resumption is trivial when usage windows reset.
Verify before claiming in multi-agent flows. Pre-claim verification step: re-fetch issue, check for closed linked PRs, check for recent claim comments, only then post claim.
Spec Docker image needs up front. Keep a single requirements list of every tool the container must have, updated whenever a gap is found.
On the Horizon
Self-coordinating parallel agent swarms
Eliminate duplicate-claim race conditions and merge conflicts by building a true coordination layer where agents atomically claim tickets, detect overlapping file touches before starting, and auto-rebase. Scale from a handful of PRs per loop to many more without supervising.
Autonomous PRD-to-shipped-feature pipeline
Chain existing skills (PRD decomposition, ticket-loop, test-harness, architecture-review) into one autonomous pipeline: drop in a PRD, agents decompose it, run multi-persona reviews, dispatch implementation agents with TDD, auto-verify via the harness, and merge, triggered by a single command.
Test-harness-driven iteration loops
The Dart shelf harness is the foundation for a closed-loop system where agents iterate against real app states until behavior matches a spec. Agent gets a bug report, reproduces it via a harness profile, writes a failing test, iterates while watching screenshots, and only stops when visual and functional assertions pass.
Fun Ending
Claude played Snake by BFS until it scored a perfect 10/10, after first dying repeatedly due to MCP latency. In a playful session, I asked Claude to play Snake. Initial attempts using MCP tools had too much roundtrip latency, so the snake kept dying. Claude pivoted to direct socket communication with per-step BFS replanning, achieved a perfect game, then packaged it up as a reusable script and agent guide.